本问题主要以Top.BatchNorm转为Top.Scale为例,展示如何添加一个Top层算子的Rewrite Pattern。

1 Answers
一. 声明
在tpu-mlir/include/tpu_mlir/Dialect/Top/IR/TopOps.td文件中定义Top.BatchNorm算子时设置"let hasCanonicalizer = 1"使TableGen生成BatchNormOp::getCanonicalizationPatterns方法的声明。
def Top_BatchNormOp: Top_Op<"BatchNorm", [SupportFuseRelu]> {
let summary = "BatchNormalization operation";
let description = [{
...
}];
let arguments = (ins
AnyTensor:$input,
AnyTensor:$mean,
AnyTensor:$variance,
AnyTensorOrNone:$gamma,
AnyTensorOrNone:$beta,
DefaultValuedAttr<F64Attr, "1e-05">:$epsilon,
DefaultValuedAttr<BoolAttr, "false">:$do_relu,
DefaultValuedAttr<F64Attr, "-1.0">:$relu_limit
);
let results = (outs AnyTensor:$output);
let hasCanonicalizer = 1;
}
二. 实现
在 tpu-mlir/lib/Dialect/Top/Canonicalize 路径下创建与算子同名的cpp文件BatchNorm.cpp。该文件中主要用于实现:
1. 针对该算子的OpRewritePattern结构体
- 结构体由OpRewritePattern派生,需要使用OpRewritePattern::OpRewritePattern命名空间;
- 需要实现matchAndRewrite方法,输入值是BatchNorm算子以及一个PatternRewriter,返回值是LogicalResult {success(), failure()},前者表示匹配成功,执行重写操作,后者则为失败,退出当前Pattern并且不会对算子进行任何更改。
struct TopBatchNormToScale : public OpRewritePattern<BatchNormOp> {
using OpRewritePattern::OpRewritePattern;
LogicalResult matchAndRewrite(BatchNormOp op, PatternRewriter &rewriter)
const override {return success();}
}
-
通过TopOps.td 可以查看到一个标准的Top.Scale算子的输入除了Input外还有Scale与Bias Tensor,因此我们首先需要获取BatchNorm中的mean,variance,gamma和beta,并将其按以下公式计算转换为scale与bias的值
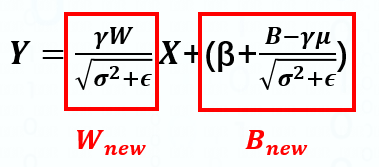
-
之后基于scale与bias两个vector创建相应的WeightOp,再通过rewriter.replaceOpWithNewOp方法将当前的BatchNormOp替换为ScaleOp,该方法所需的参数主要有:
- 用于替换的算子;
- 新的Output Type;
- 新算子的输入Inputs。
完整的matchAndRewrite代码如下:
LogicalResult matchAndRewrite(BatchNormOp op,
PatternRewriter &rewriter) const override {
auto mean = cast<WeightOp>(op.getMean().getDefiningOp());
auto variance = cast<WeightOp>(op.getVariance().getDefiningOp());
auto mean_f32 = mean.read<float>();
auto variance_f32 = variance.read<float>();
auto shape = module::getShape(op.getInput());
auto channel = shape.size() > 1 ? shape[1] : shape[0];
std::shared_ptr<std::vector<float>> gamma_f32;
if (auto gamma = dyn_cast<WeightOp>(op.getGamma().getDefiningOp())) {
gamma_f32 = gamma.read<float>();
} else {
gamma_f32 = std::make_shared<std::vector<float>>(channel, 1.0f);
}
std::shared_ptr<std::vector<float>> beta_f32;
if (auto beta = dyn_cast<WeightOp>(op.getBeta().getDefiningOp())) {
beta_f32 = beta.read<float>();
} else {
beta_f32 = std::make_shared<std::vector<float>>(channel, 0.0f);
}
std::vector<float> scale(channel);
std::vector<float> bias(channel);
// constructe scale and bias by params of BatchNorm
auto eps = op.getEpsilon().convertToDouble();
for (int i = 0; i < channel; ++i) {
scale[i] = 1 / std::sqrt(variance_f32->at(i) + eps) * gamma_f32->at(i);
bias[i] = -mean_f32->at(i) * scale[i] + beta_f32->at(i);
}
auto scale_type = RankedTensorType::get({channel}, rewriter.getF32Type());
auto scale_op = WeightOp::create(op, "scale", scale, scale_type);
auto bias_type = RankedTensorType::get({channel}, rewriter.getF32Type());
auto bias_op = WeightOp::create(op, "bias", bias, bias_type);
// replace the BatchNorm Op
rewriter.replaceOpWithNewOp<ScaleOp>(
op, op.getOutput().getType(),
ValueRange{op.getInput(), scale_op, bias_op});
return success();
}
2. getCanonicalizationPatterns
- 用于将上一步中实现的Pattern添加到PatternSet中,若存在多个Pattern则以 “,” 隔开。这些Pattern会在生成Top层mlir时被应用到转换过程中。
void BatchNormOp::getCanonicalizationPatterns(RewritePatternSet &results,
MLIRContext *context) {
results.insert<TopBatchNormToScale>(context);
}
三. 测试
通过创建一个包含BatchNorm算子的onnx模型进行模型转换,对比*_origin.mlir和*.mlir文件中是否实现了从BatchNorm算子到Scale算子的转换。创建onnx算子时请参照ONNX算子官方文档
1. 在test_onnx.py中注册单元测试
class ONNX_IR_TESTER(object):
# This class is built for testing single operator transform.
def __init__(self, chip: str = "bm1684x", mode: str = "all", dynamic: bool = True):
Y, N = True, False
# yapf: disable
self.test_cases = {
#########################################
# ONNX Test Case, Alphabetically
#########################################
# case: (test, bm1684x_support, bm1686_support, cv183x_support)
"BN2Scale": (self.test_BN2Scale, Y, N, N),
2. 创建测试样例
def test_BN2Scale(self, case_name):
input_shape = [1, 65, 100, 100]
output_shape = [1, 65, 100, 100]
weight_shape = [65]
gamma_data = np.random.randn(*weight_shape).astype(np.float32)
beta_data = np.random.randn(*weight_shape).astype(np.float32)
mean_data = np.random.randn(*weight_shape).astype(np.float32)
var_data = np.random.randn(*weight_shape).astype(np.float32)
input = helper.make_tensor_value_info("input", TensorProto.FLOAT, input_shape)
output = helper.make_tensor_value_info("output", TensorProto.FLOAT, output_shape)
gamma = helper.make_tensor('gamma', TensorProto.FLOAT, weight_shape, gamma_data)
beta = helper.make_tensor('beta', TensorProto.FLOAT, weight_shape, beta_data)
mean = helper.make_tensor('mean', TensorProto.FLOAT, weight_shape, mean_data)
var = helper.make_tensor('var', TensorProto.FLOAT, weight_shape, var_data)
bn_def = helper.make_node("BatchNormalization", inputs=["input", "gamma", "beta", "mean", "var"], outputs=["output"])
graph_def = helper.make_graph([bn_def],
case_name, [input], [output],
initializer=[gamma, beta, mean, var])
self.onnx_and_test(graph_def)
3. 在命令行中运行测试
test_onnx.py --case BN2Scale
4. 查看结果
对比BN2Scale_origin.mlir与BN2Scale.mlir的结果,可以观察到BatchNorm算子确实被转换为Scale算子。
BN2Scale_origin.mlir
#loc = loc(unknown)
module attributes {module.chip = "ALL", module.name = "BN2Scale", module.state = "TOP_F32", module.weight_file = "bn2scale_top_f32_all_origin_weight.npz"} {
func.func @main(%arg0: tensor<1x65x100x100xf32> loc(unknown)) -> tensor<1x65x100x100xf32> {
%0 = "top.None"() : () -> none loc(#loc)
%1 = "top.Input"(%arg0) : (tensor<1x65x100x100xf32>) -> tensor<1x65x100x100xf32> loc(#loc1)
%2 = "top.Weight"() : () -> tensor<65xf32> loc(#loc2)
%3 = "top.Weight"() : () -> tensor<65xf32> loc(#loc3)
%4 = "top.Weight"() : () -> tensor<65xf32> loc(#loc4)
%5 = "top.Weight"() : () -> tensor<65xf32> loc(#loc5)
%6 = "top.BatchNorm"(%1, %4, %5, %2, %3) {epsilon = 1.000000e-05 : f64} : (tensor<1x65x100x100xf32>, tensor<65xf32>, tensor<65xf32>, tensor<65xf32>, tensor<65xf32>) -> tensor<1x65x100x100xf32> loc(#loc6)
return %6 : tensor<1x65x100x100xf32> loc(#loc)
} loc(#loc)
} loc(#loc)
#loc1 = loc("input")
#loc2 = loc("gamma")
#loc3 = loc("beta")
#loc4 = loc("mean")
#loc5 = loc("var")
#loc6 = loc("output_BatchNormalization")
BN2Scale.mlir
#loc = loc(unknown)
module attributes {module.FLOPs = 650000 : i64, module.chip = "ALL", module.name = "BN2Scale", module.state = "TOP_F32", module.weight_file = "bn2scale_top_f32_all_weight.npz"} {
func.func @main(%arg0: tensor<1x65x100x100xf32> loc(unknown)) -> tensor<1x65x100x100xf32> {
%0 = "top.Input"(%arg0) : (tensor<1x65x100x100xf32>) -> tensor<1x65x100x100xf32> loc(#loc1)
%1 = "top.Weight"() : () -> tensor<1x65xf32> loc(#loc2)
%2 = "top.Weight"() : () -> tensor<1x65xf32> loc(#loc3)
%3 = "top.Scale"(%0, %1, %2) {do_relu = false, relu_limit = -1.000000e+00 : f64} : (tensor<1x65x100x100xf32>, tensor<1x65xf32>, tensor<1x65xf32>) -> tensor<1x65x100x100xf32> loc(#loc4)
return %3 : tensor<1x65x100x100xf32> loc(#loc)
} loc(#loc)
} loc(#loc)
#loc1 = loc("input")
#loc2 = loc("output_BatchNormalization_scale")
#loc3 = loc("output_BatchNormalization_bias")
#loc4 = loc("output_BatchNormalization")
注意:实际应用过程中tpu-mlir/lib/Dialect/Top/Canonicalize/Scale.cpp中的Pattern还会将Scale算子进一步转换成DWConv算子,所以在添加Pattern的时候需要确定其是否与其它Pattern相关。
rewrite pattern中返回值success和failure的问题可以参考问题https://ask.tpumlir.org/questions/10010000000000024/tian-jia-permutedao-zhi-rewrite-patternshi-zhi-xing-duo-ci-zhong-xie