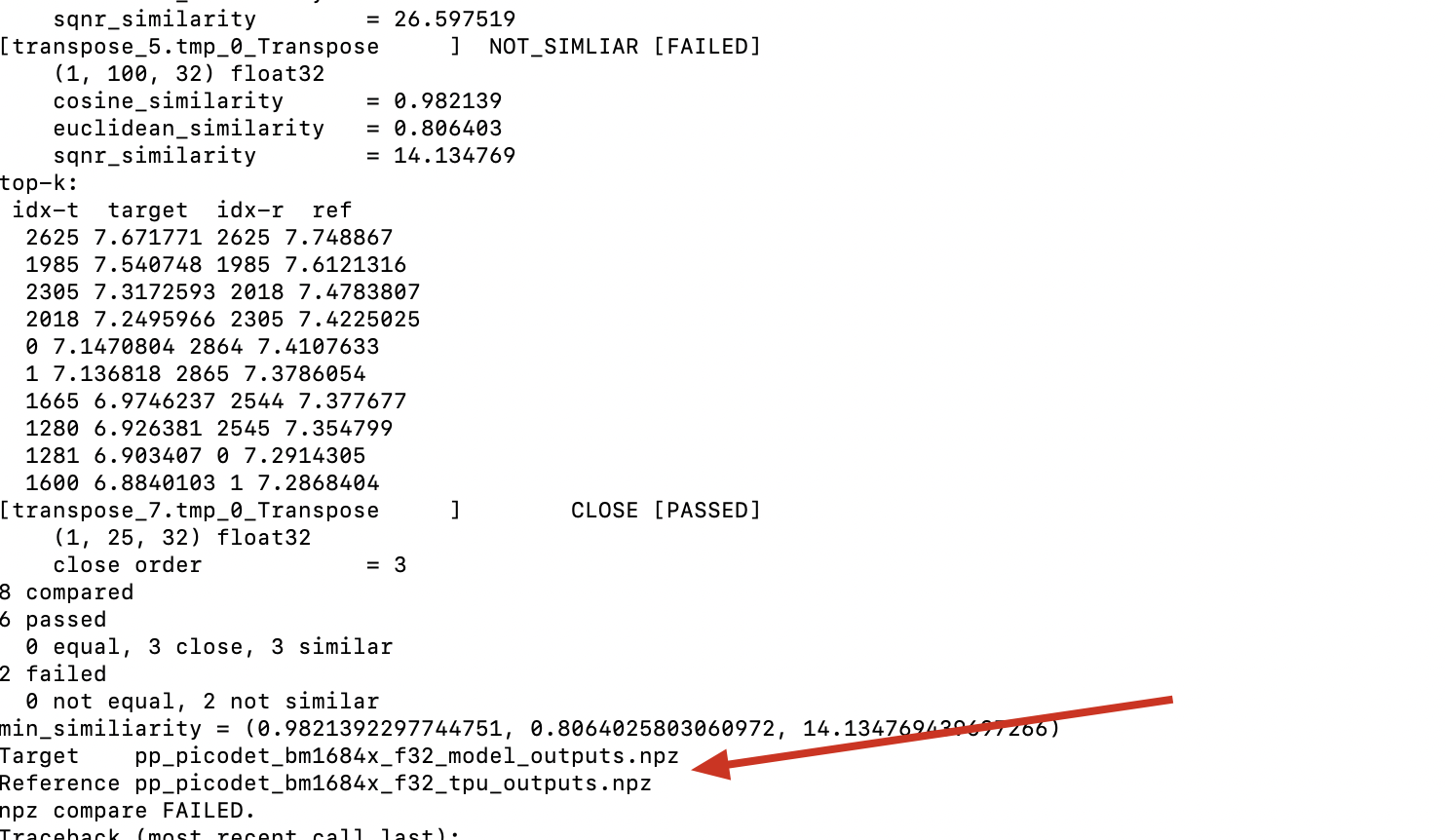
问题如图:
1 Answers
定位过程:
分析一:判断layer group是否有影响,关闭layer group,查看结果是否依然对比不过?
再跑一次看结果,结果依然是不对,说明与layer group没有关系。后续定位都关闭layer group,可以减少定位复杂度。
分析二:这是一个多输出模型,transpose_5.tmp_0对应的结果不过,我们指定只输出它,如下:
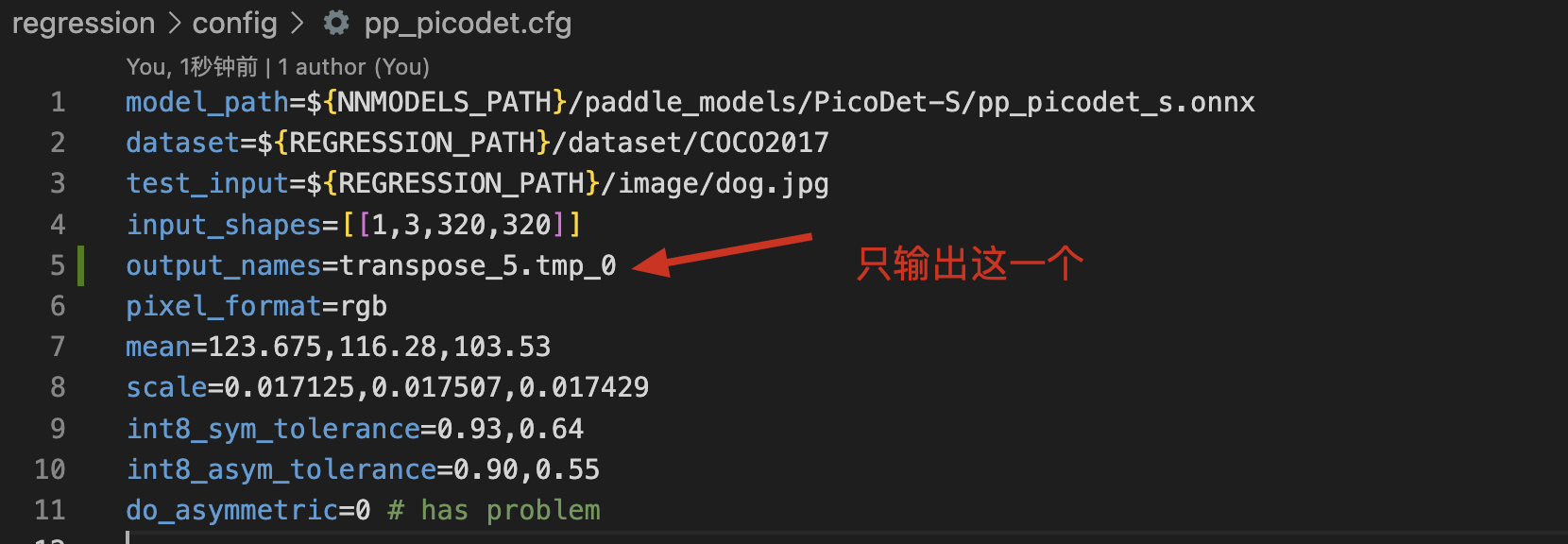
结果是对的。然后依次验证其他输出,发现都是对的。说明网络的中所有算子运算过程都没有问题。这里就怀疑有算子踩了物理内存,或者物理内存分配有冲突。
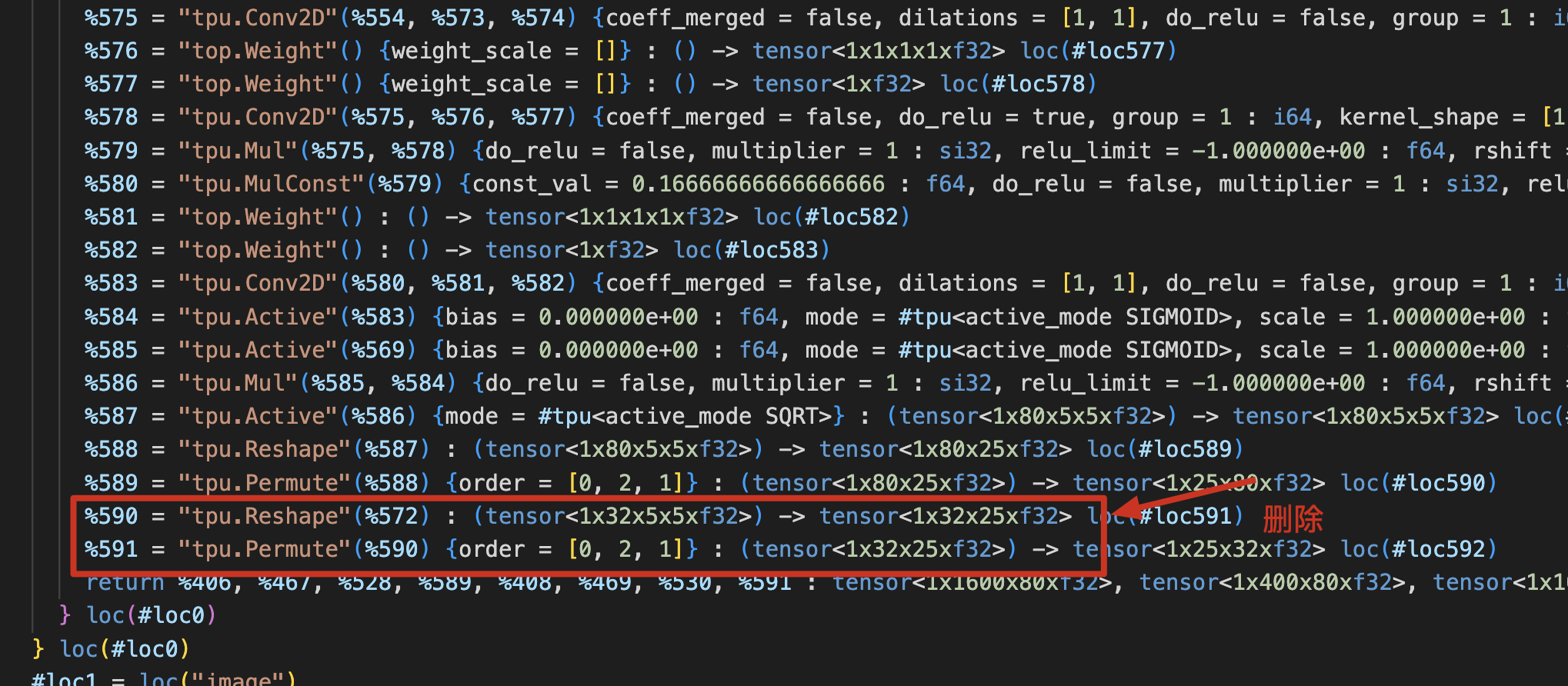
分析三:网络比较大,直接去计算哪里地址冲突会比较繁琐,采用将final.mlir (注意一定是final.mlir,且递减时weight不要去掉)逐层递减方式,生成bmodel和验证,如下:
然后执行如下命令验证结果:(这些命令在编译中都有提示)
tpuc-opt pp_picodet_bm1684x_f32_final.mlir --codegen="model_file=pp_picodet_bm1684x_f32.bmodel" > /dev/null
model_runner.py --input pp_picodet_in_f32.npz --model pp_picodet_bm1684x_f32.bmodel --output pp_picodet_bm1684x_f32_model_outputs.npz
npz_tool.py compare pp_picodet_bm1684x_f32_model_outputs.npz pp_picodet_bm1684x_f32_tpu_outputs.npz --tolerance 0.99,0.90 -vv
一直删到如下Pool2D算子为止,就OK。包含算子就失败:
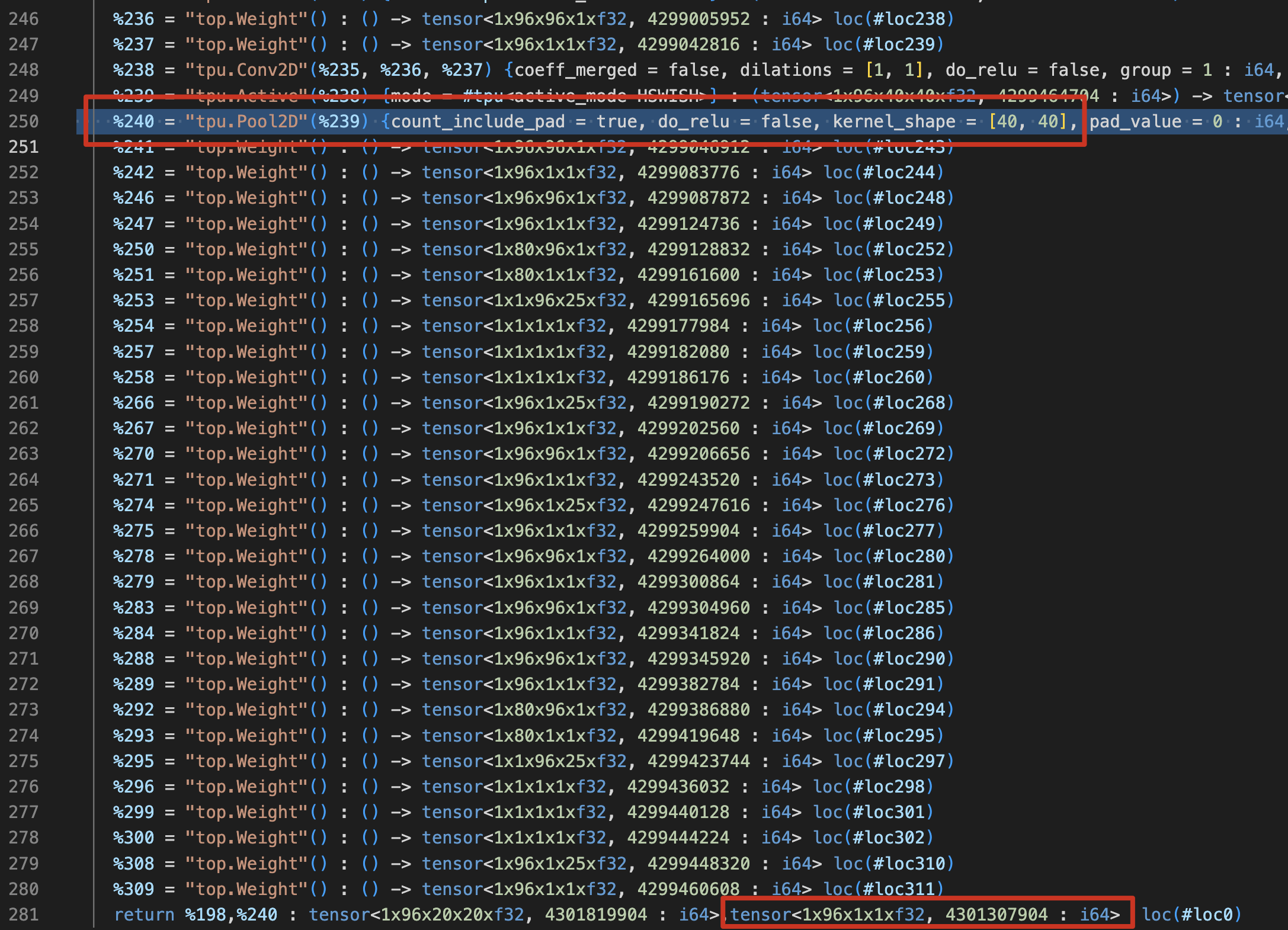
对比结果特点是Pool2D的结果是对的,另一个输出结果不对;但是删除Pool2D,其他结果都是对的。
对比物理地址,没有冲突,所以怀疑是Pool2D踩了前面输出的内存。
分析四:使用gdb定位到Pool2D的后端实现,命令如下:
gdb --args tpuc-opt pp_picodet_bm1684x_f32_final.mlir --codegen=model_file=pp_picodet_bm1684x_f32.bmodel
然后到Pool2D的地方设置断点,然后运行到这个Pool2D的断点处,断点如下:
b Pooling2D.cpp:132
注意这个是最后一个Pooling2D,运行到此处后,再对L2S的接口设置断点(能踩gmem的就这类接口),如下:
b tpu_gdma_cpy_L2S
b tpu_gdma_matrix_L2S
然后运行,每次中断后计算shape和output的gmem,判断是否踩内存:
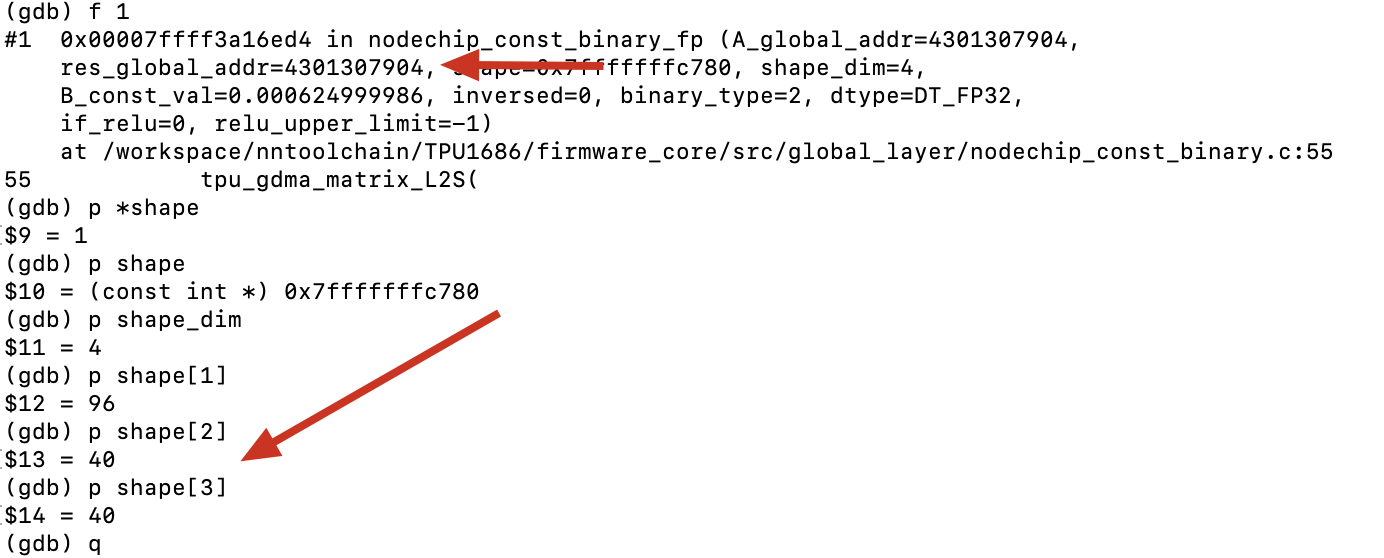
最后发现是4301307904 + 19640404 = 4301922304,数据范围是[4301307904, 4301922304]踩了前一个输出4301819904的内存。
通过bt查看调用栈,最后定位到是传入给reduce的shape不正确导致的;修正后问题解决。